Abstract: According to the characteristics of current mainstream electronic paper reader hardware resources, low power consumption, gray scale display, etc., a PPT format document analysis scheme is proposed. Focusing on satisfying people's basic needs for mobile reading, selecting text, graphics and images as basic analytical objects, designing and implementing a PPT format engine suitable for electronic paper readers, and performing multiple optimizations to improve performance experience. The end of the hardware configuration and limited runtime to complete the format resolution.
Keywords: electronic paper reader; format analysis; mobile reading; format engine
This article refers to the address: http://
Introduction PPT (Microsoft Office PowerPoint) is an office software for editing presentations developed by Microsoft Corporation. Compared with txt, chm, etc., the format has a larger amount of information and a more complicated structure, which results in higher hardware configuration requirements. However, the current embedded terminal configuration is low, so this article focuses on meeting the basic needs of people for mobile reading, and does not consider features such as video, audio and external objects. This parser is implemented in the open source environment based on the Linux operating system. Based on embedded multi-format parsing engine system architecture and intermediate format theory, it has the characteristics of platform independence and high efficiency.
1 System Features The parsing engine is compatible with many versions, including versions such as Microsoft PowerPoint97-2003. The following describes the system features.
1 does not depend on the graphics server. The parsing engine has its own dedicated vector graphics renderer. Does not depend on a specific underlying graphics server. For example, when the graphics server of our experimental system is changed from nanoX to Qt, the parsing engine does not need to be modified.
2 high efficiency. For a general format parser, the larger the sample file, the slower the open speed, and the parser can achieve file open speed regardless of file size.
3 platform independence. The parsing engine does not draw graphics and text directly on the display device. Instead, it draws various formatting elements on a memory area and then maps the memory data to the physical device. That is, the input is a file, and the output is a bitmap of the screen size.
4 configuration flexibility. The modular design of the parsing engine is easy to port and crop. All data types are defined by macros, which are easy to configure according to the platform.
5 support handwritten comments. The parser only does content extraction and display, does not support editing and saving, and supports handwritten annotations. The handwritten annotation does not change the original document, but a new xml description file.
6 personalized interaction. The 16-channel and black-and-white brush of the electronic paper controller realizes the animation switching effect.
2 format analysis
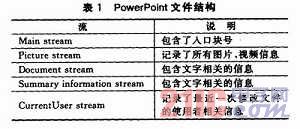
2.1 Overall Structure Microsoft PowerPoint uses OLE2 to combine document storage. Similar to the file system structure, it consists of a container and a stream, and a tree structure. Various streams are stored independently for easy loading and fast save. As listed in Table 1, the PPT file includes the following five types of streaming data.
The PPT storage format uses hexadecimal, small endian byte order, which is divided into several large data blocks and small data blocks. The sizes are 512 bytes and 64 bytes respectively. The first data block is the initial data block and is stored. Data block index table.
2.2 Image Stream Structure PPT contains 204 types of elements such as rectangles, picture frames, text boxes, lines, and ellipses, collectively called Shape. Each Shape has a unique instance code corresponding to it.
The hierarchical structure of multimedia data is shown in Figure 1.
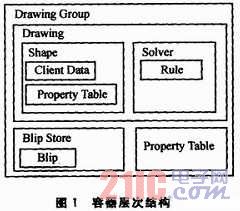
The Drawing Group is a combined graphics storage structure that contains a set of graphical objects. Drawing is a graphical storage structure, and Shape and Solver are two sets of graphical attribute metadata. The Blip Store is an inserted picture object. The Property Table is the default property sheet. Client Data is a set of metadata information, including coordinates, text and OLE data, and user-defined attribute tables.
The attribute item adopts the id-value structure, and the length of the custom attribute table is variable. The relative positions of the attributes are unchanged. Properties that appear in the custom property sheet override the default property.
Drawing is a set of rules that describe the graphical objects in a container, including alignment, rulers, and so on.
3 Software Design This design is based on the embedded multi-format parsing engine system architecture. The parsing engine is the module responsible for parsing the source files and generating the data needed by the intermediate format.
The internal architecture of the parsing engine is shown in Figure 2.
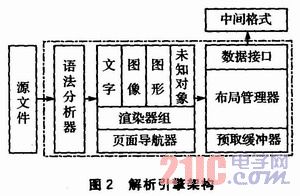
3.1 Parser The parser is input stream data, and the output is structured data for each module. The PPT format records use the id-value structure, id and value occupy the specified number of bytes, and the parser is responsible for identifying the record id and extracting the value.
3.2 Navigator is responsible for transferring data from the file system into memory and converting the I/O stream into structured data, ie using the DOM structure to describe the overall architecture of the file.
This module has a page navigation function. PPT uses OLE2 combined document storage. Containers and nodes only store coarse-grained index information. For pages that do not need to be displayed immediately, only the container nodes are stored, and they are not expanded temporarily. When the page needs to be displayed, it is expanded downward from the node, thereby reducing unnecessary File reading. This layered loading method increases the speed of opening, and for large documents, the speed of entry is only related to the complexity of the first page.
In addition, in order to better index, a series of linked list structures have been established. Such as: data block index table, root directory table, image data stream linked list, user reverse linked list, text chain, motherboard linked list, and so on.
Information such as file length, version number, and file legality is obtained by reading the initialization block. In addition to this, you need to initialize several important global linked lists.
1 data block index table. Files are stored in blocks and are not continuous. The block number and intra-block offset of the data can be easily addressed.
2 Build a root table, including the starting block number and size of the stored content, for addressing operations. The read operation is only in the current block range. When the current block readable length is exceeded, the block number of the next block is found by querying the block index table.
3 Build an image data stream list.
4 build a user reverse linked list. For fast storage, PPT uses incremental storage, which means that each time you save, a copy of the page is directly generated and appended to the end of the document. The disadvantage of incremental storage is the large amount of redundancy. For example, some files have only a few pages, but the file size is a few megabytes or even tens of megabytes, and the actual size of the file is related to the number of modifications.
5 slide text chain, stream information to typesetting metadata independently stored. Plain text is stored in the text stream, and storage and layout information is stored in the page data area. The page data area also stores the location of plain text in the text stream.
6 mother board linked list, the mother board is generally used as a background, stored sequentially in units of pages. Because the electronic paper displays grayscale images, the background and text overlays are not clearly visible, and the user can remove the background without reading the file itself.
The basic idea of ​​incremental storage is that each modification generates a user information, stores the modified block number, and the current user information points back to the previous user information, thereby forming a user reverse chain. The last modification can be found by traversing the user's reverse chain. Redundant data can be discarded directly.
3.3 Layout Manager Responsible for screen partitioning and layer management. The layout manager is divided into different rectangular areas and identifies the type of the area. Then map the parsed text, graphics, and image buffers to the screen bitmap.
3.4 Word Processor The type and layout of the text in the PPT format is relatively complicated. It can be divided into two types: text and graphic embedded text. The layout of the title text at each level is also required. The word processor parses and layouts the variety of layout formats of various texts, and completely reproduces the layout information of the original document.
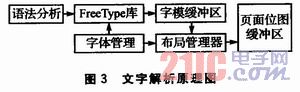
The word processing process is divided into two parts: pre-typesetting and page layout. The pre-typesetting is responsible for filling the font buffer, extracting the character encoding and font information as the input of FreeType, and filling the buffer with the generated single font bitmap. Then combine the ruler and map it to the page display buffer. The text parsing schematic is shown in Figure 3.
3.5 Graphics Rendering Responsible for graphics drawing and combined graphics coordinate space conversion. This parsing engine does not rely on the graphics server and has a dedicated vector graphics rendering library. Ability to draw graphics directly into the page bitmap, regardless of physical display.
The straight line, curve and polygon fill are respectively used by the classic Breshman algorithm, the cubic Bezier curve line algorithm and the column scan polygon filling algorithm. In order to improve the efficiency of the operation, the floating point number is rounded. It has been verified that better rendering results can be achieved on embedded systems with poor floating-point arithmetic efficiency.
The Drawing Group contains a set of graphic objects that use the Dom structure. The child node uses the coordinate space relative to the parent node. Therefore, graphics processing can recursively transform coordinates and draw the graphics in the coordinate space of their parent nodes.
3.6 Image Rendering The image renderer uses the Cximage image library to reconstruct image data and further convert it into grayscale images into the screen buffer.
The image and multimedia information in the file are stored in the image stream and described by FBSE (File Blip Store Entry). Then the structure is defined: 
4 Optimizing the speed of speed Users always want the system to be as fast as possible, but the embedded system is limited by the lower frequency and smaller memory. It is difficult to achieve the desired effect for some jobs with large calculations. Therefore, the parsing engine is applying an optimization strategy of a multi-page buffer mechanism and an asynchronous parallel mechanism.
Each renderer works asynchronously in parallel, and the first renderer that completes the task immediately submits the data to the screen display. The refresh rate of the whole screen of the electronic paper is 1 s. With this screen intermittent, the rest of the renderer completes the task, and then the partial refresh screen is used to refresh the incremental portion to the screen. This overall speed depends on which one is the slowest rendering speed. In addition, asynchronous execution does not block input. If the user flips the page at this time, the unfinished thread will be terminated and a new thread will be created to resolve the next page. For example, open a slide of a page of text and text, display the text first, then display the image, and will not block the user input, if the user stops after several pages in rapid succession, the intermediate page parsing will be terminated.
5 Verification The effect achieved on a 200 MHz E-paper reader is shown in Figure 4.

Randomly select 60 sample files, the minimum time to enter the book is 2.82s, the longest is 11.92s, as shown in Figure 5.
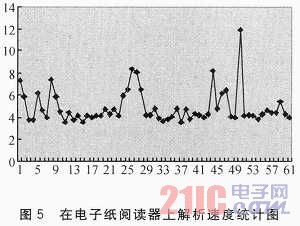
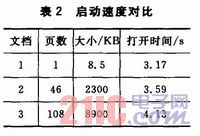
The parsing engine uses a layered loading method to improve the speed of opening books. Here, three PPT documents with the same first page but large differences in size are selected. Experiments have shown that although the document sizes vary widely, the opening speeds are not much different. As listed in Table 2.
Conclusion Due to the characteristics of electronic paper and the resource limitations of embedded devices, this article focuses only on the analysis of common elements, such as text, graphics, images, tables, etc., but does not support embedded objects (such as video, audio, etc.). The analysis of unknown elements will be the main work of the future. The modular design architecture of this paper is conducive to the next step of function expansion. In addition, with the birth of the Office Open Document Format (OOXML) and becoming an international standard, an embedded parser supporting OOXML will be developed in the future.

Noah Plus LED Grow Light, Cree LED Grow Light, COB LED Grow Light, UL Certified LED Grow Light
Shenzhen Mingxue Optoelectronics CO.,Ltd , http://www.mingxueled.com