On-demand video viewing process and source definition
On demand, it is relative to the live broadcast. The English name is VOD (Video on Demand). As the name implies, a viewer is on demand. Only the video is viewed. The content seen is the beginning of the video.
The live broadcast, whether or not there is no audience to see, the video has been moving forward, when an audience came in, is the video at that time.
On-demand video content is very diverse, with serials, movies, sports videos, videos produced from media, and even contains (now very popular) short video.
Have you ever wondered what the operation is like when you open a video on demand?
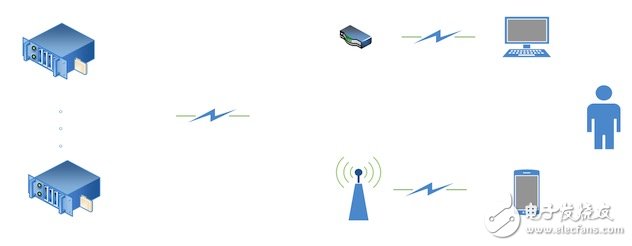
A simple point of view is this on the diagram:
Video sites provide on-demand resources such as PPTV's new series, a movie, or short video sites that offer a new short video
Visitors visit websites through web pages, apps, etc. to watch videos
In fact, the situation is not so simple
The on-demand resources provided by the video site, that is, the files, are placed on the servers of their own company. The servers may be purchased or rented.
The server cluster that stores these files is called the source station.
These video files are not actually accessed directly by users. Instead, they are distributed step by step through cdn. Therefore, these storage clusters are also responsible for connecting CDNs.
So the role of the source station is to store and dock the CDN. There is a division of labor. The video site has video copyright. The CDN is good at distribution.
Let’s take a look at the process of on-demand video sites including short videos.
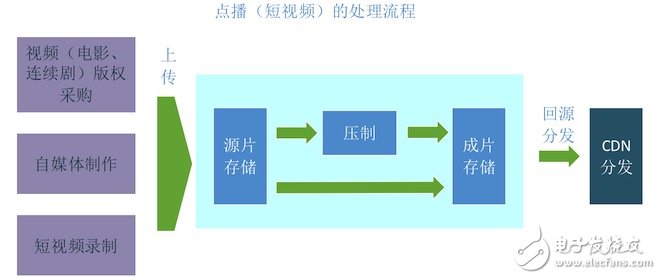
The process is as follows:
Content generation (this can be done outside of the video site). The video website purchases the copyright, or creates a video from the media author, and the short video author records the video on the mobile phone
Upload content to the video site's source storage. The video website's editor uploads and purchases the copyrighted video, and uploads its own video from the media and short video authors.
Choose whether to suppress (according to characteristics). The video site chooses whether or not to suppress the video according to the characteristics of the video. For example, a short video can generally be played on a mobile phone without suppression, and a movie series generally suppresses a multi-rate code rate.
Stored in pieces. Video that is suppressed (or not pressed) is called a movie and stored
Back to the source. The CDN downloads these videos back to the viewer
Source station and CDN network topologyWe know that there are the following facts:
A (video) video of a video site is not usually placed in only one computer room. For example, the PPTV video and sports classes will be placed in Shanghai's engine room. The reason is that the sports studio is located in Shanghai. The local recording is convenient and does not require internet bandwidth. The movie and television classes are all placed in the engine room in Wuhan because the editing center is in Wuhan.
A video site will connect multiple CDNs, and may also build a CDN on its own. Such as PPTV, on the basis of their own CDN, and domestic and foreign well-known CDN manufacturers have in-depth cooperation
Each CDN (including self-built) vendor's corresponding network access point location, quality has a lot of differences
In addition, for a video site, a video file is only used to save one or two copies (of course, video companies will do hot and cold backup operations, etc., so, in fact, not only so little storage, and this detail belongs to the storage of high availability Is not going to get into the category,)
In order to store in different rooms, only one piece of data is sent to multiple CDNs at the same time, and the source station needs to use a multi-level cache structure.
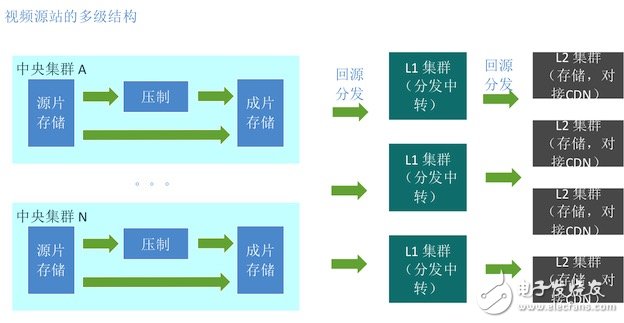
Between the multi-level cache inside the video source station, that is, the distribution among multiple rooms, is called internal distribution;
The distribution of video source stations (L2 clusters) to CDN access points is called external distribution. Generally, the L2 cluster is connected to the CDN access point. When the L2 cluster is interconnected with the CDN, it will select a good line, even in an operator's room.
Therefore, the focus of our introduction is still how to distribute video files from N pieces of storage clusters to K L2 clusters through K L1 clusters.
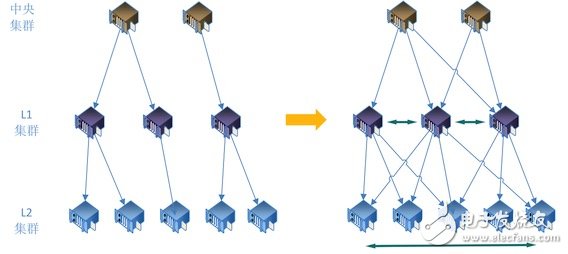
On-demand video source station distribution process, there are problemsWhen the on-demand video is distributed from the central cluster to the L1 and L2 clusters (machine rooms), the tree-like distribution is used (the establishment of this tree will be based on experience or the characteristics of the network itself), and the quality of each central node to a different L1 room is greatly different. The quality of different L1 to L2 rooms varies greatly
The distribution process takes the Internet line (excessive leased line), the stability of the Internet line is unpredictable, and sometimes the network jitter will cause the distribution to fail. Even the accident that a dry network is cut due to the fiber optic cable being cut off will occur frequently. Or a room problem may create regional unavailability
When different clusters (laboratories) plan and build, the capacity of servers (calculation, storage, and IO) and the bandwidth of the entrance and exit are different. The number of nodes corresponding to different clusters is also inconsistent when they are distributed downwards, and there will be large differences in load among different clusters. The situation, commonly known as busy busy idle, busy node, is likely to become a bottleneck

On-demand video source station distribution link optimization
How to solve the problems mentioned above, we naturally think that if each file distribution process can automatically select the best link, instead of the dead source tree according to that configuration, then the distribution process will be Bring these advantages:
More efficient and stable to avoid regional failuresThe load of different clusters (machine rooms) is more reasonable and average
Why evaluate the distribution quality between two server nodes first
The previously mentioned optimization method is to choose a good distribution link. Then, how to distribute the link is a good link? Let us first look at the following facts:
The link is composed of server nodes through which data passes
In the link, the worst transmission quality of adjacent server nodes determines the quality limit of the distribution link
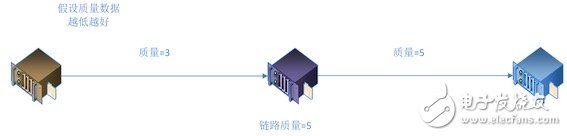
So, we first study the transmission quality between two server nodes.
Transmission quality assessment between two server nodes
So, what is used to evaluate the quality of the transmission between two server nodes, we naturally want to have a quantitative data, a simple idea is "file download time."
There are several factors that affect the transmission quality (download time) between two server nodes:
File size
The network lines between servers, including data delay, packet loss rate, hop count, etc.
Current load of sending server (receiving server), including CPU load, memory usage, IO load, current bandwidth, storage usage
current time
We will briefly analyze how these factors affect downloads.
File size: The larger the file, the slower the download and the longer it takes
The situation of network lines between servers: the network conditions between two servers, specifically these indicators
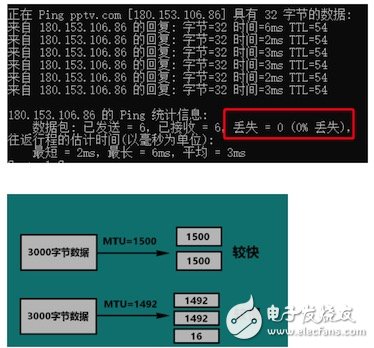
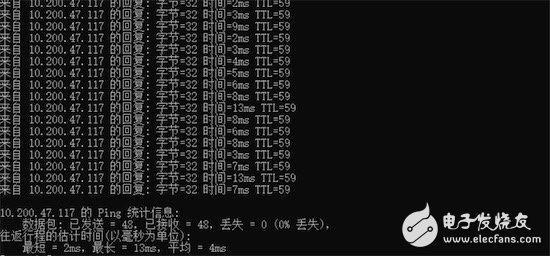
Delay: The ping command in the figure below can test the delay information between two servers. For data transmission, the delay is as small as possible
MTU (Maximum Transmission Unit): The maximum packet size (in bytes) that can be passed over a layer of a communication protocol. The maximum transmission unit parameter is usually related to the communication interface (network interface card, serial port, etc.). As shown in the figure below, 3000 bytes are transferred. If mtu is set to 1500, two packets need to be marked, and when mtu is set to 1492 , you need to type 3 packets. It takes more time to transmit 3 packets than 2 packets.
Packet loss rate: The ping command in the following figure shows that the current packet loss is 0. When there is a problem in the network, this data may not be 0. The video download is based on HTTP. The bottom layer is the TCP protocol. Retransmission is required after packet loss. The lower the packet loss rate, the better
Number of hops: The number of hops represents the number of routing devices that the two servers communicate with. When the data passes through the router, there will be queues of packets in the router. The queue is too full and the data is discarded. The router is counting the next hop of the packets. At the time, there will be a certain amount of time;
The server's maximum bandwidth: The server's maximum bandwidth, of course, the bigger the better (of course, the higher the cost), such as home installed broadband, 500M certainly better than 100M (and more expensive)
The current load of the sending server (receiving server)
CPU load: When the CPU load is small, it has little effect on downloading. When the CPU load exceeds a certain value, it will seriously affect the download efficiency.
Memory usage: When the memory usage is not high, it will have little effect on downloading. When the memory usage exceeds a certain value, it will seriously affect the download efficiency.
IO load: When the IO load is not large, it has little effect on download. When the IO load exceeds a certain value, it will seriously affect the download efficiency.
Current bandwidth usage: When the current bandwidth is not close to the maximum bandwidth, it has little effect on downloading. When it approaches the maximum bandwidth, packet transmission is blocked, which will seriously affect the download efficiency.
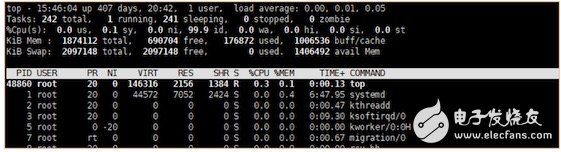
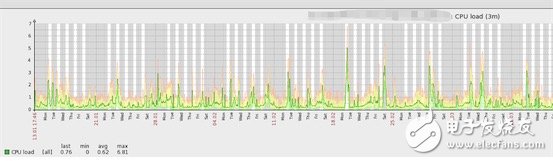
The figure shows the current machine load seen by the top command
current time:
The above-mentioned data are all jittery with time. For example, with bandwidth data, the number of people watching video sites in the morning is small, the number of people watching at night is much, and the people on weekdays are inconsistent with weekends. With new features, the overall internet usage trend is upwards, so from a long-term perspective, bandwidth data should fluctuate upward.
There is a problem to be mentioned here. It is precisely because of the same size, download speed of the same link, and the performance difference at different time points is huge, it is necessary to introduce a dynamic estimation mechanism.
For example, if a file is 2G in size, we think link A is the best before we start downloading. However, after downloading 300M, the quality of link A is not good. This is because link B may be better. The goal that we want to achieve is to figure out which of the following is the minimum time to download the 2G size file.
The idea of ​​establishing a data transmission quality model between two nodesMeasure the distribution quality between two nodes, we can use a value, download time (Download TIme, abbreviated as DT) to represent, this data is affected by many specific factors (variables) that show a certain law over time, then we can There is a good idea: use a model, or a function, to describe the relationship between these factors and the DT. When the new file is downloaded, use this model, enter the current variables, and predict the download time of the file.
Assume the function is as follows:
DT = Func(file_size, current_TIme, defer, cpu_load, mem_load, io_load, ....)
We know that a file size is 100M, the current time point is known, these variables are known between nodes, we can calculate the length of time according to this function.
Third, the design and implementation of machine learning algorithmsIntroduction of machine learning
The idea of ​​building a model (function) was proposed earlier to predict DT. How can this model be established?
We first look at how mathematics is done. In the category of mathematics, for a set of independent variables and dependent variable data, the process of reversing the function is called fitting.
In a two-dimensional space, an independent variable and a dependent variable are simple curve fittings.
Three-dimensional space, two independent variables, one dependent variable, surface fitting,
In N-dimensional space, N-1 independent variables and 1 dependent variable can also be fitted.
These specific algorithms are available in mathbooks, and the least squares method is available for interested students to view on their own.
In the area of ​​computer science, pioneers of AI research proposed the use of neural networks as a method of machine learning to deal with this problem.
What is machine learning? There are many explanations on the Internet. We will explain here briefly.
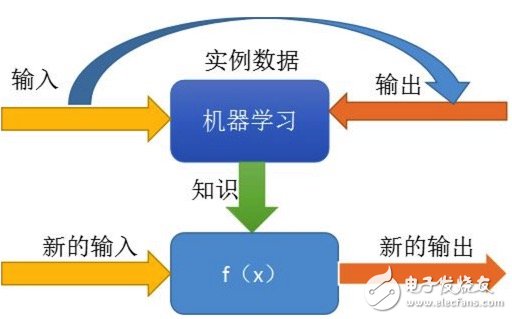
We give the machine (the program on the computer) the known input and output, let it find the law (knowledge discovery), and then we let it calculate the new output with the new input according to the found rule, and to this output The results are evaluated, if you are right, you are encouraged. If the results are not appropriate, you can tell the machine that it is not right and let it find the law again.
In fact, this process simulates or implements human learning behaviors to acquire new knowledge or skills, and reorganizes existing knowledge structures to continuously improve their performance.
The essence of machine learning is to let the machine analyze a model to represent the laws (functions) hidden behind these data based on the existing data.
How to achieve this process of finding the law?Let us first describe how mathematics establishes a function (how to do a fitting). The process is as follows:
Select the fitting function (power function, exponential function, logarithmic function, trigonometric function, etc.)
Setting parameters
Comparison error, adjustment parameters
Iterative
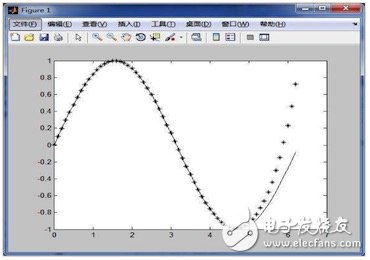
For this series of points in the figure, we first felt that the arrangement of these points is sinusoidal. Then we use the sine function in the trigonometric function to fit it, and set the period, amplitude, phase and other parameters of the function. You and later found that after x 5, there is still some error, which needs to determine that the error is acceptable, if not, you need to do a new fitting.
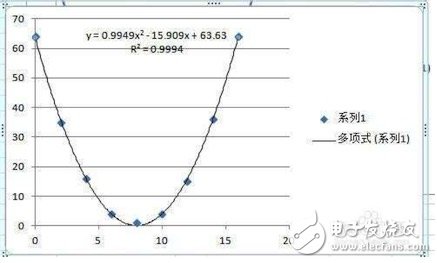
For the fitting of these points in the above figure, we find that the distribution of these points is like a parabola. According to our mathematics knowledge in middle schools, the parabola is an image of the power of the second power function, so the use of the second power function to do the fitting And finally get an equation.
As in the field of mathematics, in the AI ​​world, input is transformed into output through a model (function). The model (function) is determined by what, guess!
Guess is not a problem, the question is how to guess more accurate?
The pioneer of AI proposed the idea of ​​simulating human brain neurons to deal with how to guess the problem of the model
Neural network and artificial neural networkThe brain neurons look like this:
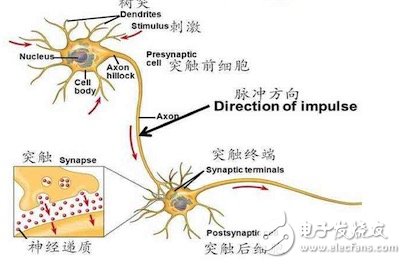
The neural network of the brain looks like this:
The characteristics of brain neurons are such that each neuron is only responsible for processing a certain input, making a certain output, giving it to lower nodes, and finally combining them to form a neural network in the human brain, which is the process of animal thinking.
The artificial neural network is artificially constructing some processing nodes (simulating brain neurons). Each node has a function that processes several inputs and generates several outputs. Each node is combined with other nodes and synthesized into a model (function). .
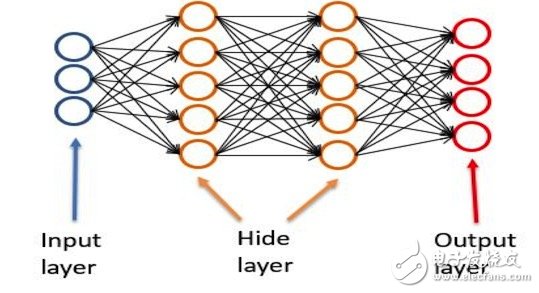
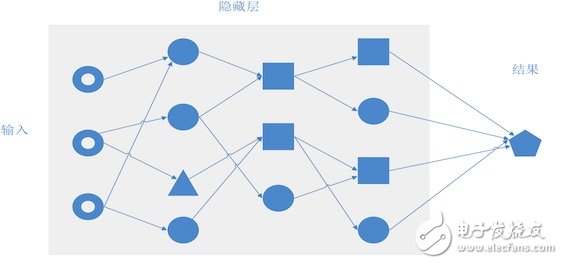
From left to right are the output layer, hidden layer, and output layer.
The input layer is responsible for the input, the output layer is responsible for the output, and the hidden layer is responsible for the middle of the calculation process.
Each node in the hidden layer is a processing function. The structure of the hidden layer, that is, the number of layers, the number of nodes, or the function of each node will determine the processing result of the entire neural network.
Introduction of TensorflowTensorflow's introduction is very much online (you can search to view), according to the context of this article, we briefly introduce the following:

Tensorflow is a platform for deep learning through neural networks. We give it input, output, and some (guessing model) rules, allowing him to help us guess specific models.
The steps for using TensorFlow can be summarized simply by collecting training data and training iterative comparisons.... .
Training data collection
Let's introduce how to collect training data for a model that establishes the transmission quality between two nodes.
As mentioned earlier, data is divided into input and output data.
The input data is 4 types:
Downloaded file size - can be directly recorded
Current time - Use unix TImestamp
Statistics of network conditions - from some speed measurement tools
Send (receive) server load conditions - records from zabbix
The output data is the time record of downloading a file, which needs to be discretized (the reason for discretization is introduced later).
Zabbix's introduction:
Enterprise-class open source solutions for distributed system monitoring and network monitoring based on WEB interface
Zabbix can monitor various network parameters to ensure the safe operation of the server system; and provide a flexible notification mechanism to allow system administrators to quickly locate/solve various problems
Zabbix server with optional components zabbix agent
Supports Linux, Solaris, HP-UX, AIX, Free BSD, Open BSD, OS X
Zabbix's anget is deployed on the transmission node and regularly collects the load and bandwidth usage data of the machine and summarizes it to the zabbix server.
The following figure is the zabbix statistics for the current bandwidth:
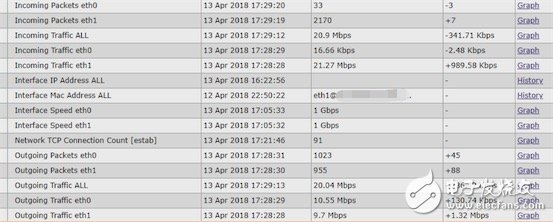
The following figure shows the 3-month bandwidth load:
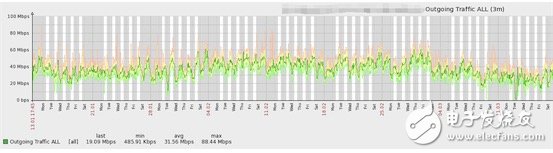
The following figure shows the 3-month cpu load:
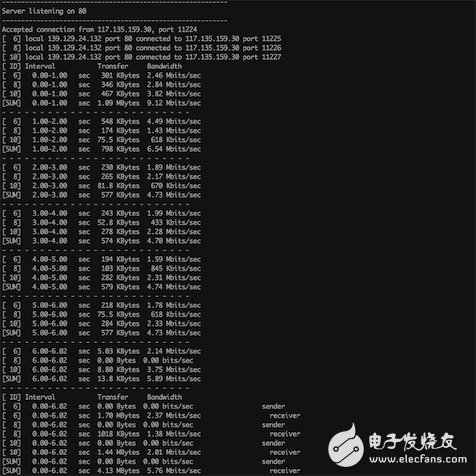
Use the IPERF tool to collect network data
The IPERF tool can collect the following data:
Transmission bandwidth between current servers
Packet loss rate
MSS, MTU
Support tcp/udp
The following picture shows the use of iperf screenshots:
The Ping tool collects delays and tests node connectivity:
Tractroute tool collects inter-node hop information
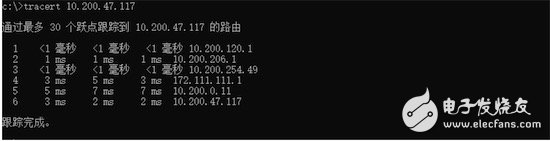
(in windows cmd, the command is tracert)
Preparation for training
Data combination and formatting:
The network data, load data, file size, time, formatted into a json.
The time-consuming download data is segmented and then discretized. Here we explain why the results (outputs) are discretized. TensorFlow is good at classifying learning. When the result set of the classification is a continuous set, possible results. There are infinitely many, which will greatly increase the difficulty of training and reduce the speed of training. The discretization of the results is good, the time close to the time is processed into a value, and the time over a certain threshold value is converted into a value, so that the range of results is limited, which will greatly reduce the difficulty of training.
Training model parameter presets:
When we talk about the fitting of the mathematical category, we first select one or more combinations from the power function, trigonometric function, exponential function, and logarithmic function according to their own (meng) test (meng). Foundation.
For a neural network, we can't just ignore it and let it guess. Instead, we need to set the model and parameters based on the geng (meng) test (meng).
As mentioned earlier, each node is a function, then, what function we choose, we first consider the simplest case, the linear function, we use a bunch of linear functions combined into a network, this network description model, affirmative Still a linear model, it is not enough to describe most of the world's laws.
The following figure is a common linear function:
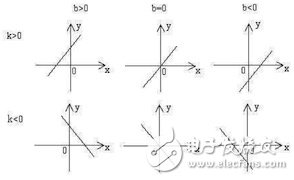
Then we consider that the non-linearization of each function is to add a non-linear function (called the activation function) and a network in addition to a linear function. This network description model can basically cover Most of the world's laws (don't ask me why, I don't know...).
The following figure shows some of the commonly used nonlinear functions:
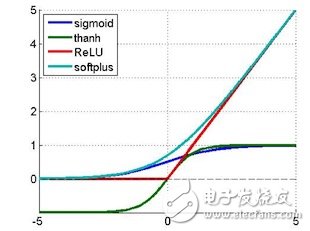
Constituted network:
For each type of function on each node, we guessed one first. Then, the structure of the network uses several layers and several nodes at each level. This is a matter of choice when it comes to neural networks in different fields.
When evaluating the transmission quality between nodes, we first set the number of layers according to (brain) examinations (gates) to be 15 and 50 nodes per layer. Node functions are also set according to basic experience.
The following parameters will affect the TensorFlow training results:
Initial learning rate
Learning rate decay rate
Number of hidden layer nodes
Iteration rounds
Regularization coefficient
Sliding Average Decay Rate
Batch training quantity
Linear function, activation function settings
Among them, the number of hidden layer nodes, number of iterations, number of batch training, linear function, and activation function settings will have a great influence. How to set them has already been mentioned above, while the remaining parameters have little influence, and interested students can search on their own.
TensorFlow process flow
Single node processing as shown below:
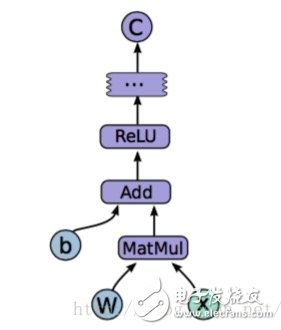
A node makes ReLU(Wx+b) and then combines with other nodes to generate the final output.
It is divided into the following steps as a whole:
data input
training
Training result review
Adjustment parameters
Retrain
Training result review
......
Satisfactory training results
Calculate the optimal transmission path using Tensorflow's results
After we had a lot of training and tuning, we got a training model between every two (needed) server nodes. Through this model, we can calculate an expectation by entering the current file size, time, server and network test status. The download transfer takes time.

We substitute the results of the two-by-two calculations between nodes into the network topology.
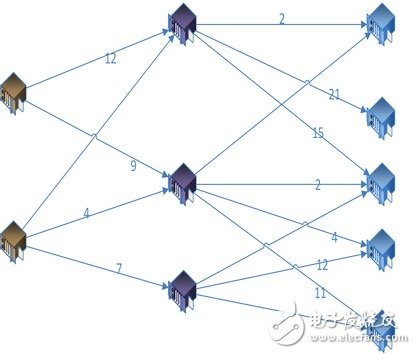
Use the shortest path algorithm to calculate the optimal (and sub-optimal) transmission path
Here is the Dijkstra algorithm (translated to Dijkstra's algorithm)
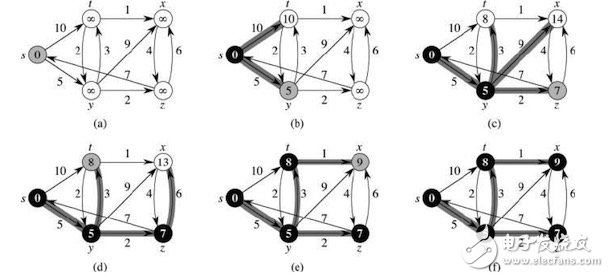
This is a very classic shortest path algorithm. It does not take up space. Interested students can search on their own.
Overall process review
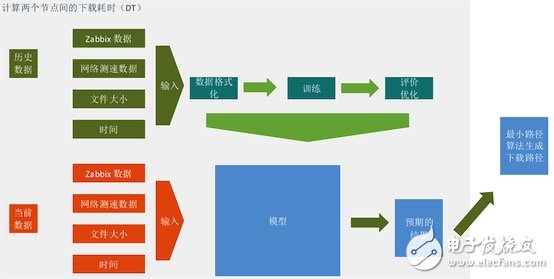
First, collect training data, use zabbix data, network speed data, file size, and current time information as input, download time-consuming as output, perform model training, and continue to optimize the model.
Use the current zabbix data, network speed data, file size, and current time information as input, and use the trained model to do calculations to get the expected download results.
Relevant nodes, which calculate the expected results in pairs, form a transmission network and use the Dijkstra algorithm to calculate the minimum path within the transmission network.
Fourth, the future outlookUsing the Maximum Flow Algorithm for File Fragmentation Download
The current algorithm is aimed at downloading the entire file. In fact, the streaming media server already implements virtual file cutting, and the http protocol also has a range request. On this basis, a file is split and downloaded simultaneously through multiple links. Increasing download speeds will also further increase network utilization.
Specific reference EK algorithm, Dinic algorithm.
Maximizing the maximum flow algorithm using the minimum-cost maximum flow
Taking into account each room, the cost of each line is different.
When there are multiple sets of solutions for the maximum flow, each unit adds a unit cost amount, and when the maximum flow is satisfied, the minimum cost is calculated, so that the cost will be more refined, and the room needs to be expanded. guide.
Application in live broadcasting
At present, the on-demand source station distributes internally, the input data used for model training is the above data, and the result is download time; for live broadcast, data related to live broadcast can be used for combination and training, and the result is QoS, a new model is generated, The optimal link is predicted for internal scheduling of live broadcast sources.
External Rotor Motor,Outer Rotor Motor,External Rotor,External Rotor Fan
Wentelon Micro-Motor Co.,Ltd. , https://www.wentelon.com